The Evolution and Structure of Distributed Platforms: Part 1

Table of Contents
Distributed systems are currently being churned out in record numbers. Solutions to fundamental problems around building, deploying, and maintaining these systems have matured to the point that agile companies can bring a new offering online in a matter of months and manage to avoid major outages.
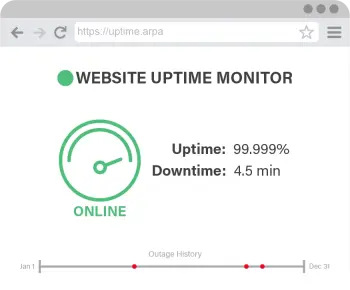
As a coworker says, 9.9999% is still 5 9’s of uptime.
Over this series of posts, I’ll discussing practices that make a successful platform, and how the history of the industry has shaped it all.
Platform Topology
Before anything, let’s dig into the factors that led to the current state of platform engineering. Most companies that have been conducting any level of non-trivial business since the twenty-teens or before will most likely have a similar technology stack that has evolved based on similar business and technological pressures over the years. Usually, at the core of this structure is a legacy monolithic system that historically supported most of their profitable business. There has also probably been a push to modernize or move away from that monolith which has run up against the reality of how disruptive, time-consuming, and expensive it would be to replace the legacy stack. Maintaining existing revenue streams is what keeps the lights on, and no sane company would risk their livelihood just to jettison bad technology.
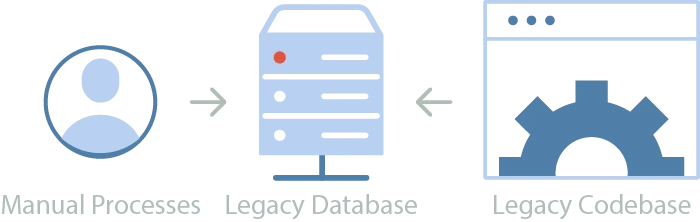
The general structure of a monolith comprised of scheduled/manual processes, a database, and a codebase that acts as both a frontend and a backend
✖
The general structure of a monolith comprised of scheduled/manual processes, a database, and a codebase that acts as both a frontend and a backend
Going back a decade or so, we saw many companies using a core monolith of code sitting on top of a growing database of private data. Additionally, a small set of business-critical processes would be carried out either on a schedule or manually by the engineers. Taken as a whole, this mixture of code, data, and process constituted the company’s competitive offering.
As time went on, features continued to be added to the monolith, making the system increasingly overloaded and brittle. Alongside code sprawl, data continued to accumulate, which strained the database infrastructure. In response to this growing pressure, the monoliths were scaled vertically, moving the application and database onto increasingly beefier servers. That worked just well enough, until around 2012 when the demand to offer mobile alternatives started to grow. This created a new stress on monolithic applications. The structure of using the codebase to create views into the database suddenly needed to make room for new views, clients, and infrastructure. Separate codebases and workflows needed to be developed to power responsive websites and mobile apps, and they needed to retain the specific look-and-feel of the main offering. Unfortunately, many of the existing features were spread across the codebase, unable to be directly accessed by new apps, and impossible to be extracted into a shareable component without extreme effort and risk.
Shifting to Microservices
Around this time (around 2011-2013), a new trend that purported to solve these difficulties started to get a lot of buzz - and of course I’m talking about microservices. The idea was extremely compelling - if you were to build each of your business’s critical features as a separate service, it would be trivial to create new versions of your current offerings that just reuse those services. Beyond that, there’s a multitude of other potential benefits: Isolation would guarantee that one faulty piece of code couldn’t tank your entire system; The impact of changes would be much more localized, preventing far-reaching consequences like regression bugs or full outages; Teams could operate with greater momentum and less cross-dependence. I could keep listing reasons that microservices have outperformed their monolithic predecessors. Oddly, what I can’t do is concretely define the term microservice. At least not in a way that would be universally applicable across all companies/frameworks/languages. My best effort is this:
- Microservice
noun [mī-(ˌ)krō sər-vəs]- An application with a specific theme that’s meant to interact with other applications and be smaller than the previous platform that was built.
It’s also difficult to say whether or not something that began as a microservice and grew exponentially over time in size and responsibility could continue to be considered a microservice. Maybe a better label for those would be “Macroservices”.
But now that I’ve sung the praises of microservices and attempted to nail down what they are, let me jump to the downsides. You see, it was naive to think that a large tech stack with active users could just be converted from a monolith to microservices as a matter of course. As I alluded to earlier, it takes far too much time and money to achieve that to ever make sense in a tech department’s budget or timeline. It would effectively mean you had to freeze all feature development while you figured out how to rebuild everything. And at the end of this, you would have a product that does exactly what the product you have today does. It’s indefensible from a business sense, and probably not as worthwhile from a technology sense as you’d hope.
So what did companies actually end up doing? For the most part, they carried the flag of “microservices over monoliths” and started making new, smaller systems which they tried to integrate with the monolith. It would probably be more appropriate to label those systems as “distributed monoliths” than as legit microservices.

Distributed monolith systems keep the existing monolith at the center and deeply coupled to new microservices to offer new or improved features.
✖
Distributed monolith systems keep the existing monolith at the center and deeply coupled to new microservices to offer new or improved features.

As companies shifted to a concurrent monolith/microservice architecture, engineering shops that used to support a single infrastructure ended up supporting two or three integrated infrastructures. So the drive to make things simpler by migrating to microservices actually forced a growth in operational complexity that drove the creation of a new type of engineering.
Birth of Devops
As these systems started to mature, it started to take more engineers to keep the infrastructure working. Changes in more repositories needing to be deployed more often caused outages and all types of bugs. Engineers found themselves having to work on multiple codebases to support a single application, and not everyone could fully manage the sysadmin aspect of deploying their changes. They also found that the work it took to host and deploy the monolith was now doubled or tripled. Much more could go wrong, and when things did, that meant more outages. We responded by creating devops roles for engineers who would specialize in the system architecture and how changes got deployed. Devops engineers created new tooling to aide in the developing, testing, and deploying of these hybrid systems. Tools that would grow and mature to become the foundation of today’s stable platforms.
Whereas the monolith deployment process was a hyper-specific set of steps that were known to work for deploying new versions of that particular application, we now needed the ability to deploy any number of separate, but similar, applications. To meet this need, devops abstracted out the processes and produced pipelines that could automate the testing and deployment of as many applications as necessary. It also became apparent that bespoke applications required bespoke pipelines to be deployed, but platform engineers could create a generic template that new services would be built on top of. Using those templates, devs could make an unlimited number of services and the pipeline would already know how to deploy them.
A typical CI/CD pipeline automates testing and deploying changes.
✖
A typical CI/CD pipeline automates testing and deploying changes.
Also, if you could make smaller applications that had fewer cross-dependencies, you could thoroughly test them in the CI/CD pipeline before deploying them. Even further limiting the possibility of outages.
Another breakthrough in this area was containerization. Previously, the deployment process would need to provision or reuse a server, and the pipeline would need custom scripting to place the code, install dependencies, update configuration files, deal with file permissions, and start relevant services. With dockerized containers, that definition could live alongside the application, and the “server” could be built and configured before it’s needed - frozen in time, ready to be placed on the network and unfrozen on demand. We also began to explicitly define infrastructure in code, allowing the provisioning process to be further automated.
The result of all these innovations is that we had well tested code pushed out to well managed infrastructure in a manner that prevented most issues. And when a new issue would arise, its solution would be added to the automated process, permanently preventing it from coming back.
These practices continued to mature, and over time we realized we didn’t only want to churn out microservices, we also wanted a handful of other components that could be stitched together into a larger application. For example, components that manage data replication, event handling, or file processing could be distilled down into templates, allowing engineers to use a robust technology stack while only needing to look at the small amount of custom code they need to add. In part two I’ll go into more detail on the types of components that comprise a full platform, as well as how the advent of being able to create a huge number of small parts has led to its own set of problems.
Check out part 2 now!

Dall-e generated art from the prompt: Evolving distributed computing system, digital art