The Evolution and Structure of Distributed Platforms: Part 2
Modern platforms are a product of where we came from and how much we can manage to build and maintain all at once.
Previously in Part 1, we looked at the history of platform engineering. Now let’s take a closer look at some modern day practices.
To recap the previous post, non-trivial systems originally took the shape of monoliths with a database that stored all of the data and a codebase that served the dual role of frontend and backend.
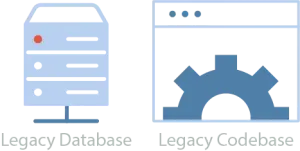
A monolith made of a database and codebase.
Eventually, smaller systems called “Microservices” were built to extend the feature set of the monolith. The monolith and microservice systems together became a type of hybrid “distributed monolith”.

Services were broken out, but still used the same database.
Moving past the monolithic core and digging into the modern systems, we’ll find templated building blocks that can be strung together to deliver new features, or to integrate with the legacy systems. Let’s start with a rundown of some basic types of components:
| Component | Description |
|---|---|
 RESTful API | Servers that are always running, normally providing a logical layer between clients and persistent storage. This type of component could potentially offer any functionality you could provide via a web request. However, complex endpoints that couple features together have generally proven to be difficult to grow and maintain. |
 Processor | Oftentimes we can distill a problem down to needing to run logic against a known input structure, and optionally generating an output. In the past this may have been accomplished in an API endpoint or a stored procedure, but it’s been proven that building, testing, and running this type of functionality in isolation is more maintainable. Processors are distilled logic with minimal scaffolding. These small pieces of logic can stand on their own, or be strung together in a larger workflow. Different processors may operate on extremely different scales. Some may process a 1kb event body every now and then, while others may process billions of rows in continual big-data jobs. |
 Data Store | Reliable, persistent storage is a common necessity. Templating relational, nosql, or graph databases so engineers can provision and deploy them without worrying about maintenance is a core feature of any modern platform. |
 File Store | Similar to data stores, reliable file storage allows for the long term accumulation of data like logs, transactions, or reports. |
 Event Publishers & Consumers | A core aspect of event driven design is the ability to publish or consume events as they happen. Publishers may produce events around user actions, changes in data, or anything else that may happen in the system. Once an event has been published to a message queue, any interested application can start responding to it by setting up a consumer subscribed to the appropriate topics. |
 Search Index | Applications that need to let users filter, sort, or page through datasets can aggregate relevant data in an optimized index which allows for fast, interactive UIs, plus common search functionality like type-ahead suggestions. |
 Frontend | Frontends are either components that can be loaded into existing applications, or free-standing applications. By templating out the frontend, major concerns like user identification and access control can be abstracted away. |
 Notifications | Parts of the application will need to contact users or administrators when certain events happen. Users will often configure their notification preferences once (ie email, text, digest, etc) and parts of the platform can push notifications to relevant users via their preferred means through a standardized interface. |
 AI / Machine Learning | AI components can help supercharge the value of existing datasets and drive new types of user interactions. The ability to streamline access to data and integrate with existing components can provide a huge competitive advantage. |
 Workflow Scheduling | Workflows coordinate the execution of a series of steps. Steps can reuse existing processors or be bespoke. Robust workflows are usually DAGs where the steps are idempotent and have configurable retry/backoff logic. |
Ideally, a platform makes provisioning a new component as simple as possible, and tooling exists to create code, infrastructure, and deployment pipelines to sling all of these components into a managed environment where they all magically work together.
Maintenance
One thing worth mentioning up front is the topic of maintenance. The need to perform maintenance can mean the difference between productive teams that regularly meet their goals and overwhelmed teams that can’t crawl out from beneath their backlogs. With the ability to easily churn out a large number of modern components comes the double edge sword of creating a large swath of disparate pieces that will need upgrades and patches.
One of the most important factors in delivering software is the race between maintenance tickets coming in against new features going out.
A healthy platform provides the ability to apply critical upgrades across a large number of components without causing downtime. Additionally, things like monitoring and logging should be built into each type of component. Adding visibility into the health of the system is critical to staying ahead of potential maintenance disasters.
Data Replication
One of the most impactful additions to modern platforms is the ability to get data from point A to point B with minimal hassle. Replicated data from the monolithic database can be used by any number of apps without adding strain to the already taxed database. In terms of paradigm shift, this means that new features can be implemented against an always up-to-date copy of data from the monolith. We can avoid adding tables or columns to the old database, and new components can be developed and tested in isolation without a direct connection to the monolith.
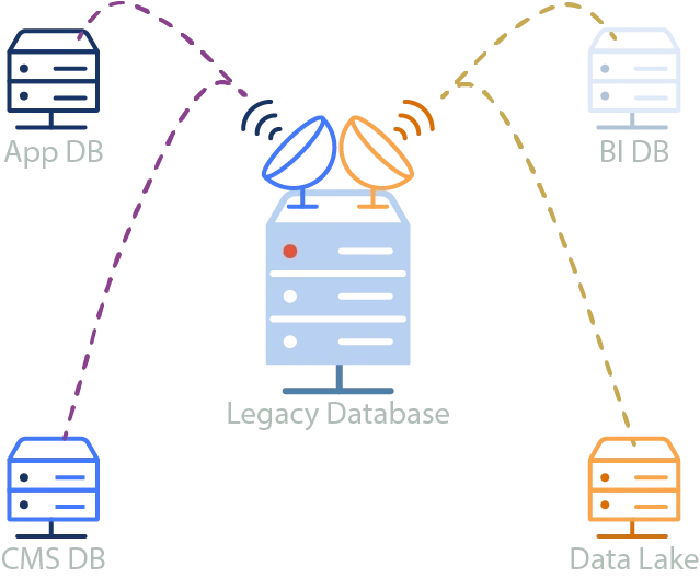
Data can easily be replicated to multiple destinations in near-realtime.
✖
Data can easily be replicated to multiple destinations in near-realtime.
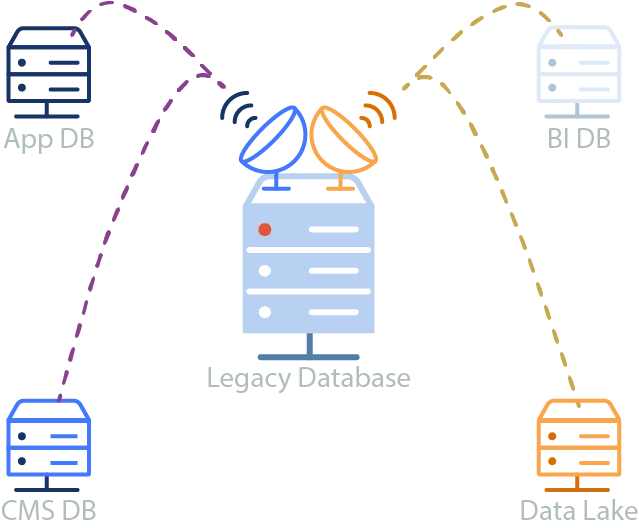
In this use-case the producers/consumers are often referred to as sources/sinks respectively. The intended meaning being that some source of data, like a database, file bucket, or even a spreadsheet can produce its changes to a message queue, and another component can sink those changes into a different system.
Eventing
Being able to detect and respond to changes in a distributed manner can help create a healthy system that engineers can hook into when adding features. Parts of the system that subscribe to updates can operate in isolation and fail/heal without degrading the entire system.
Having events that engineers can predictably find and subscribe to allows concurrent development of new features without traditional blocks or conflicts. Take the example below:
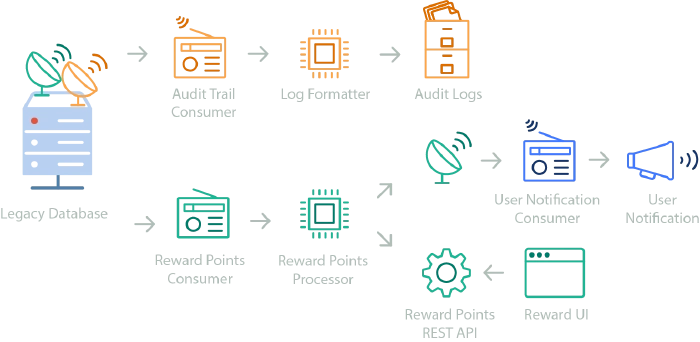
Multiple services hook into existing workflows
✖
Multiple services hook into existing workflows
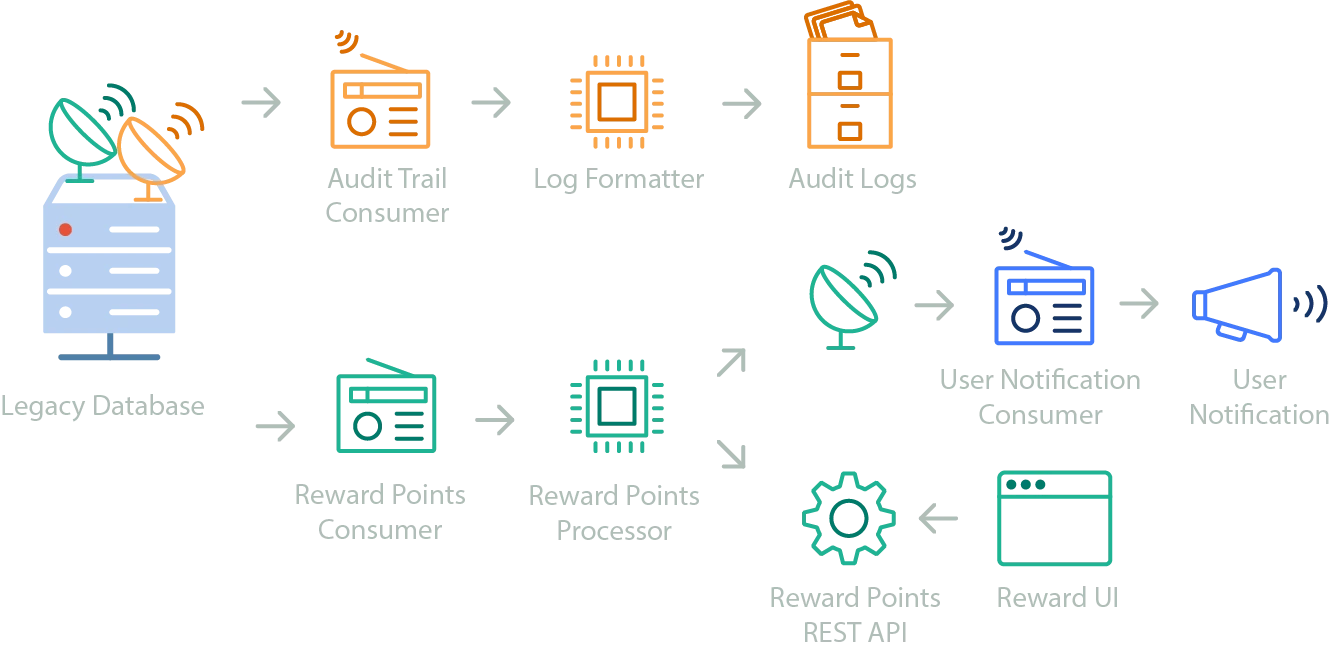
Here, changes made to the monolith database are produced to a topic. One team (in orange) has created an audit logging system that subscribes to the changes, which are pushed to a processor to be formatted and stored in persistent file storage. Each component of their system can be provisioned and managed internally by the team, without needing outside intervention from devops or anyone else. At the same time, a Rewards Points feature has been added by a separate team using their own components. Using the same topics, a separate consumer pushes the events to a Rewards Points processor, which uses its own RESTful API to record changes. When it needs to notify users of updates to their rewards status, it publishes its own events which the notifications system picks up. They also maintain a frontend UI that users can access to view the status of their reward points.
Search
Search was a hard problem in computing until it was solved with dedicated technology. Frontends that display tables of data may be able to source it from APIs or topics, but supporting full searching, filtering, sorting, paging, suggestions, and type-ahead requires dedicated technology. Templated search index clusters can be brought up with minimal effort, and combining the principles from data replication and event handling, we can create highly performant search indexes using cloud hosted solutions where the main consideration is choosing which events should trigger updates to the index. For an example, take the following diagram:
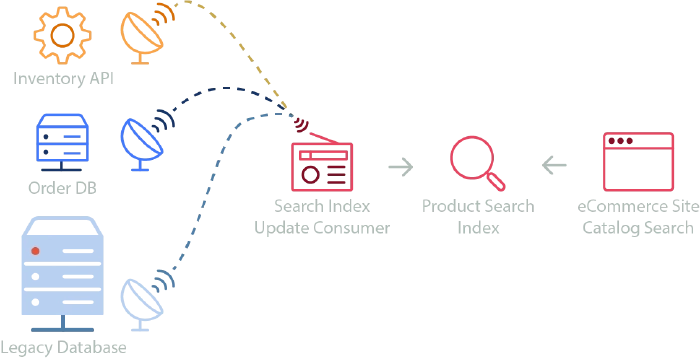
Search indexing
✖
Search indexing
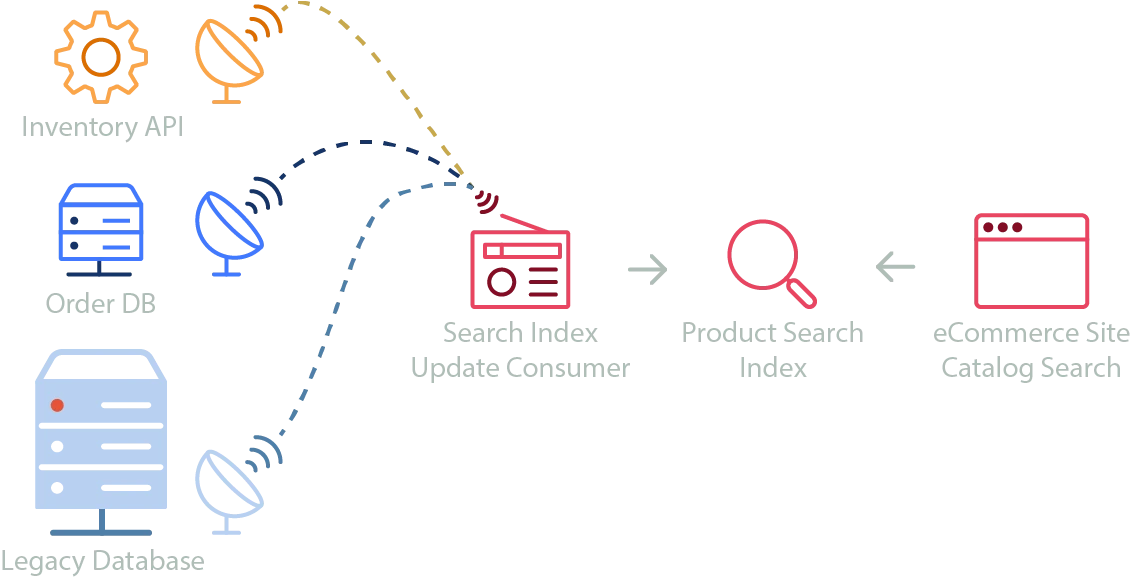
In this example, an eCommerce system offers customers advanced product filtering, including faceted catalog search. Frontend searches send queries to the search index to get products filtered by name, availability, color, size, and dimension. Results are paged in user-selected increments of 20, 50, or 100 results, and are sortable by price, average review, and popularity. A search bar is enriched with suggested search terms and type-ahead results. As new products are added to the legacy database, an event triggers its addition to the index. Updates to the inventory API trigger changes to product availability, and orders being added to the Orders Database trigger updates to product popularity. Individual teams own and operate each system and publish update events to relevant topics. The team that owns frontend search can maintain a reliable search index without needing to modify, or even really understand each distributed component. They can simply decide which events are relevant to keeping their search index up to date and subscribe to them.
Workflow Scheduling
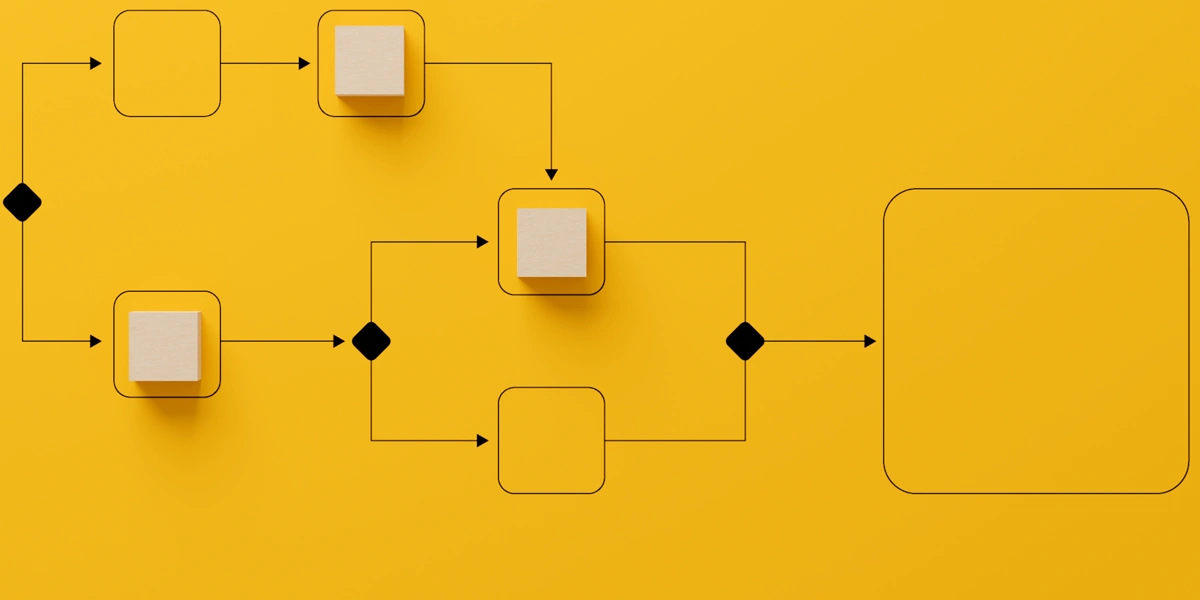
Predefined executions of smaller steps can be combined into a workflow definition. These workflows can be managed by a state machine or scheduling software. Executions of each workflow can be triggered on schedules or in response to a request/event. Each execution is tracked along with the status of the steps within the execution, giving insight into any possible issue that arises. The workflow definition handles the flow of execution, where steps wait for the previous steps to exit successfully, and decisions can be made about which step to execute based on the output of previous steps. When a step fails, the workflow configuration determines when/if it should be retried. Looking at the example below, a user-initiated workflow runs an accounting workflow to produce monthly invoices.
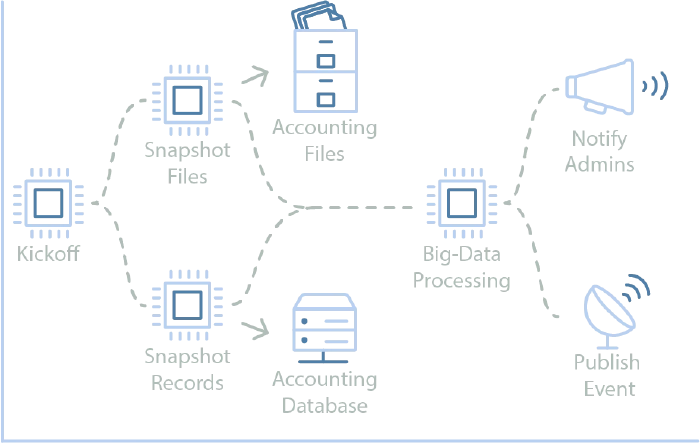
An employee initiated accounting workflow can interact with system components and guarantee correct execution of steps.
✖
An employee initiated accounting workflow can interact with system components and guarantee correct execution of steps.
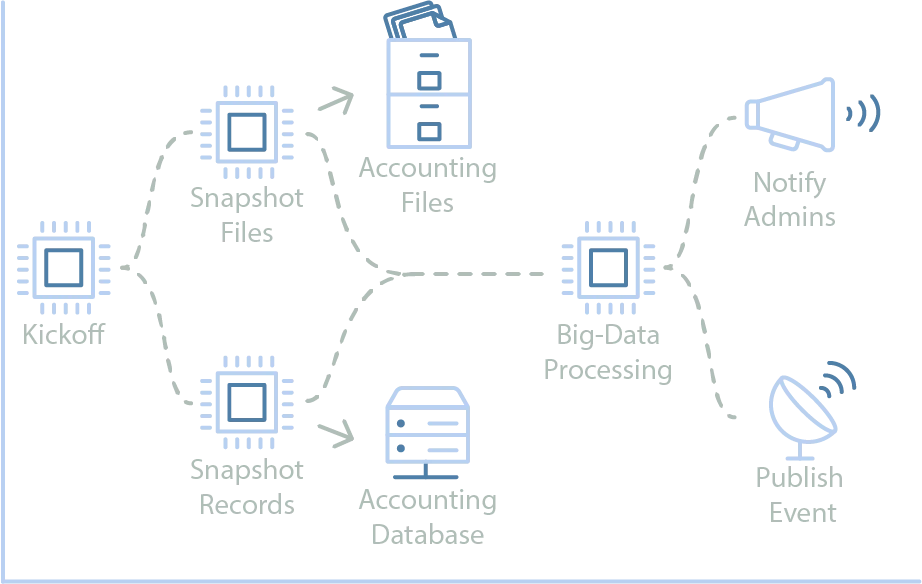
In this example, a processor kicks off the process, validating the event and setting the stage for the execution. Next, a pair of processors concurrently snapshot data from various sources into a format and location that a big-data processor can use for the actual calculations. If those both succeed, the calculation processor performs its work, producing the final invoices. Upon completion, internal users are notified and an event is published so other systems can choose to respond.
Conclusion
Composable systems are very powerful. Having mature, templated components transforms an organization, allowing a large number of small teams with less specialization to create a broad set of powerful solutions in less time than ever. The platform engineering teams can partner with these smaller teams to deliver support and new features. The next iterations of platforms will come from these teams refining the tooling around managing the complexity of creating and managing continually growing systems. Finding efficiencies around tracking, taxonomizing, and managing large sets of components will be necessary to further scale companies’ ability to grow these solutions. The solutions may involve using AI to help find, maintain, and monitor the fleet of components. Additionally, UI’s and reporting systems to view the current catalog of components need to become more mature. Stay tuned for part 3, where I’ll discuss ways of keeping track of all of these pieces and staying ahead a wave of maintenance.