Dev Blog: Building a Lyrical Password Generator

Last week, I decided to update the oldest of my personal sites that’s still online. It’s a password generating form that limits the number of times you need to switch keyboard layouts on mobile phones when entering the password (ie, lowercase alpha -> uppercase alpha -> symbol set 1 -> symbol set 2). The most recent commit was from June of 2016, so I was apprehensive about how well this would go. After pulling the repo down, trying to start it locally unsurprisingly flopped, which started me on the path to modernize the site, and ended at a complete rework of the original idea…
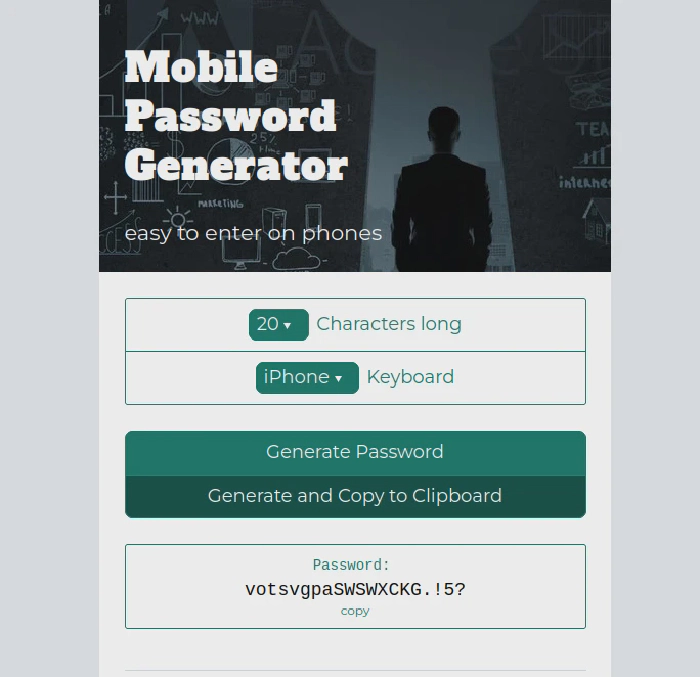
mobile-pw.xyz’s Homepage.
Right away, npm install failed with a flurry of errors, the most obvious one
relating to node-sass requiring python2.
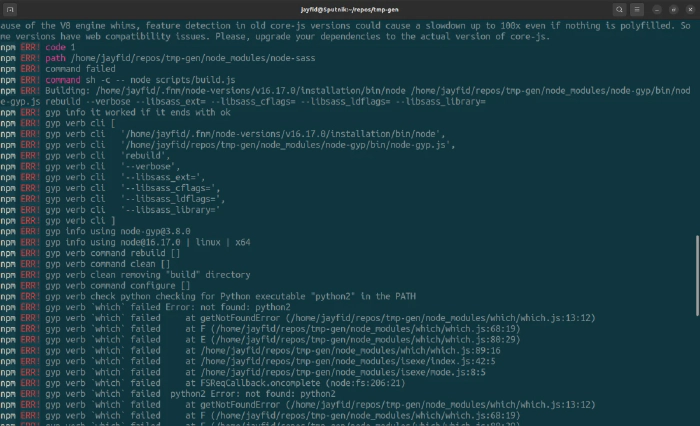
The project won’t even install locally anymore :(
✖
The project won’t even install locally anymore :(
The site was originally built using a node-sass plugin for gulp (a predecessor to webpack). Gulp’s npm repo looks to have been abandoned shortly after I abandoned this project, and I suspected fixing this error would just cause more latent issues to pop up, so the prospect of modernizing a gulp workflow in-place seemed sisyphean. Instead, I started down the path of reworking the build chain.
Once upon a time, gulp was a widely used tool that let you automate building local and production versions of your html/css/js sites. It appears that this time has long passed. Reminiscent of the lost colony of Roanoke, looking at the official sites and repos of the gulp project make it apparent that humans once occupied this space, but were driven from it in some sudden catastrophe. So the first goal became clear - reclaim the ability to build and ship this site.
Instead of revising the entire structure of the site, I created a skeleton of an empty webpack site. Starting with a live preview of an empty page, I began layering the the source files from the old site. First the HTML, then the SCSS, and finally the Javascript. When i dropped the final files in place, I again had a workable development environment.
There were a couple JS errors and eslint was clearly very unhappy, so I decided
to modernize some of the javascript - this was a js app from a time when ES6 and
React were still very early in their implementation. The site wasn’t built on
those, but I had built in approximations of bits of their functionality. Back
then, I had used my own home-brewed js/css framework that I was calling
“vinylsiding”, which was like a cross between
React without JSX and
tailwindcss without tree-shaking. I was able to
completely pull out JS utilities that have since been replaced with the addition
of classList and querySelector to DOM Elements. I replaced old class
prototyping with ES6 classes, adopted consts, and reworked traditional
functions into arrow functions. I started serving my own fonts instead of using
Typekit, and pulled out some wonky special handling of iOS clients that’s long
since been obviated. Luckily, vinylsiding’s CSS seemed to still be pretty
strong, with the only adjustments being some cleanup of outdated vendor
prefixes.
With the original site back in working order, I could again develop locally and deploy changes to the live site. Mission accomplished! As a bonus, it was a bit more organized and lightweight than the previous incarnation.
Finally, I could dig into why I had wanted to update the site in the first place - previously it could only generate passwords up to 20 characters long. I added in a couple more password length options, redeployed, and checked out the result. Everything worked! However, now there was a major usability issue staring me in the face. I could generate longer passwords that were fairly easy to enter, but now the passwords were too long to remember! It doesn’t matter if the password is easy to type in if you don’t know it :(
Discontent with leaving the project in that conflicted state, I started brainstorming on how to resolve this fundamental issue. The problem, as I saw it, was that longer passwords won’t be used without an easy way to remember them. One password scheme that I’ve found to be very easy to remember is modifying popular song lyrics. So maybe the approach here shouldn’t be to make increasingly complex random passwords, but to create entropy on top of phrases that are easy to remember.
With this in mind, I went back to the drawing board to reinvent my original solution in a way that ensures reasonable security while allowing for the user-friendly aspect of easy to remember phrases.
A quick note on the security of my solution - I recommend using a password manager when possible, but in cases where that’s not an option, I choose to use long, memorable phrases. Using a set of random words as a password creates a decent amount of entropy (as xkcd demonstrated years ago). Using song lyrics in place of random words severely reduces the entropy of the passphrase. I’ll also add some leet-speak transformations, but any good password cracking tool already accounts for that. My goal here isn’t to create the most cryptographically secure passphrase, it’s to create the most secure passphrase that I’ll actually use. In the absence of this mnemonic approach, I would certainly use and reuse shorter, less secure passphrases and likely need to store physical copies as a backup.
Implementation Phase
As for a plan of attack, it made sense to divide the problem into three pieces.
- A frontend that fetches a list of lyrics, selects one, munges it, and displays the result
- Infrastructure for an API consisting of a database and HTTP endpoint
- A way to populate the database with enough lyrics to make the app secure enough, at least for a POC
The transformation process in the frontend will be a simple “leet speak” cipher, transforming random letters in the lyric into their leet-speak equivalents. It should work similarly to this:
- INPUT: She’s got a smile that it seems to me
- OUTPUT: She’s g0t a smi1e th@t it seems to m3
To that end, a basic mapping could define which characters are replaceable.
Since the API didn’t yet exist, I stubbed out mock data while creating the UI. Quickly sketching out a potential solution, I arrived at this:
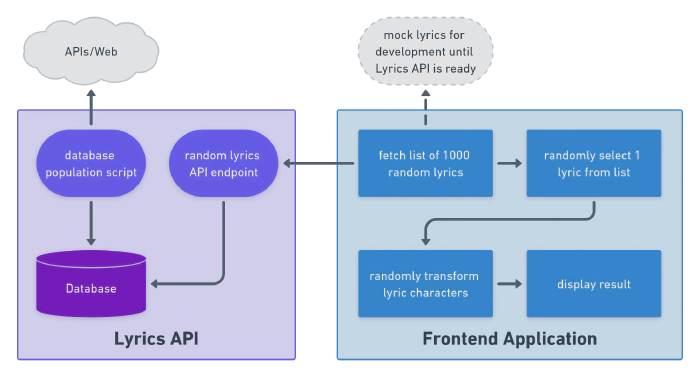
The solution can be split up so work .
✖
The solution can be split up so work .
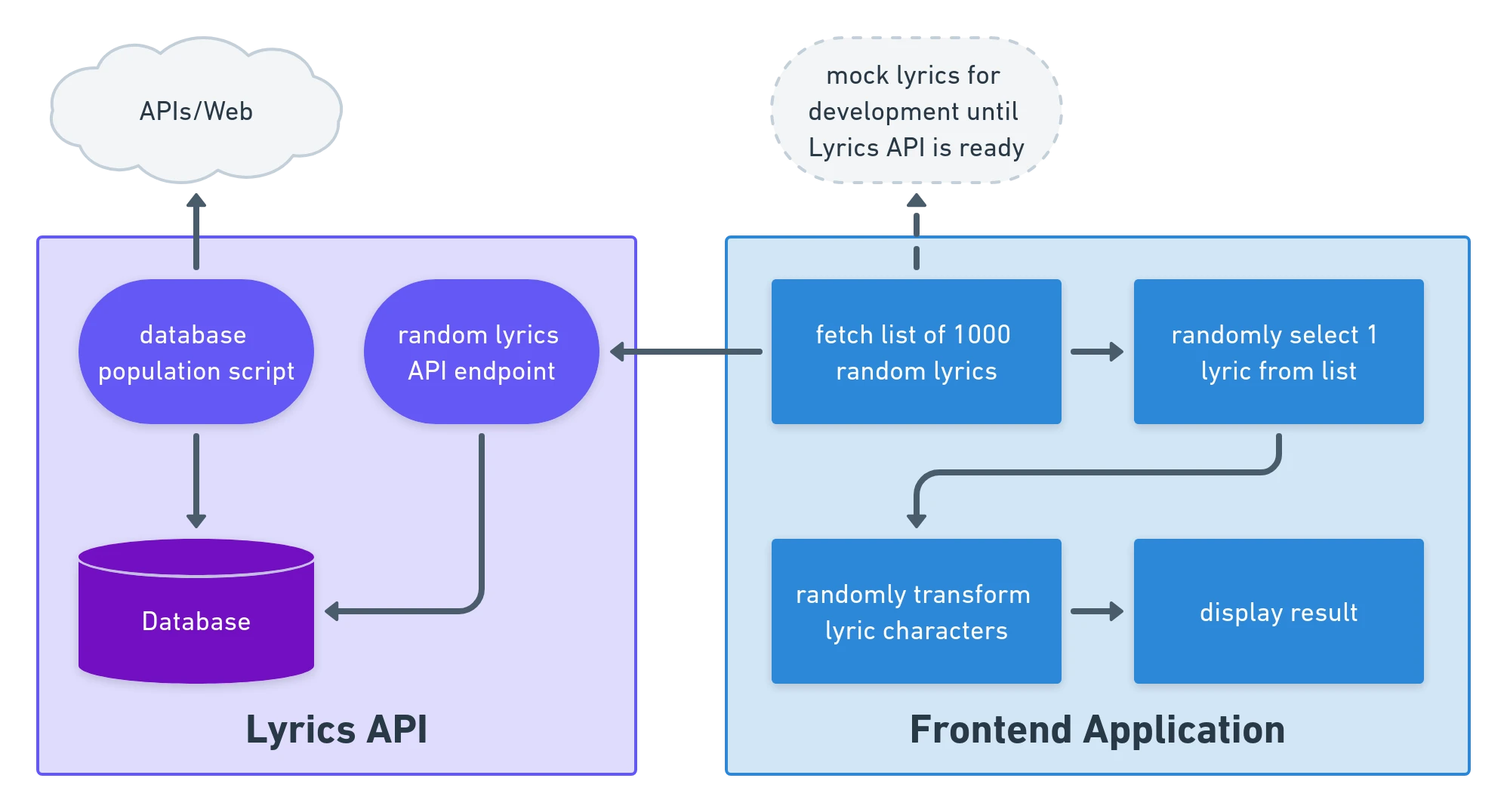
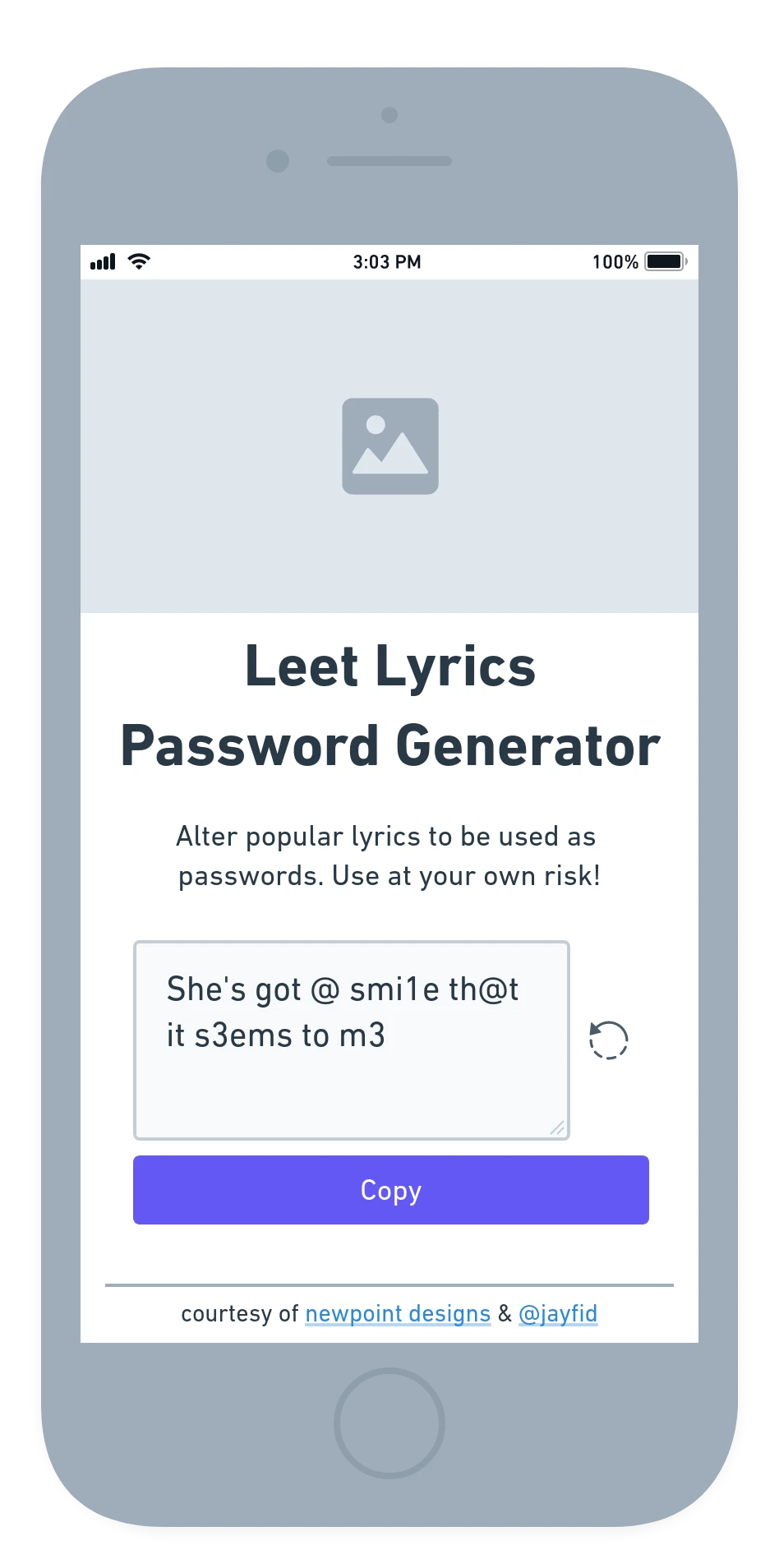
The API and frontend could be worked on separately, so I tackled the frontend piece first. I came up with a basic layout of the app:
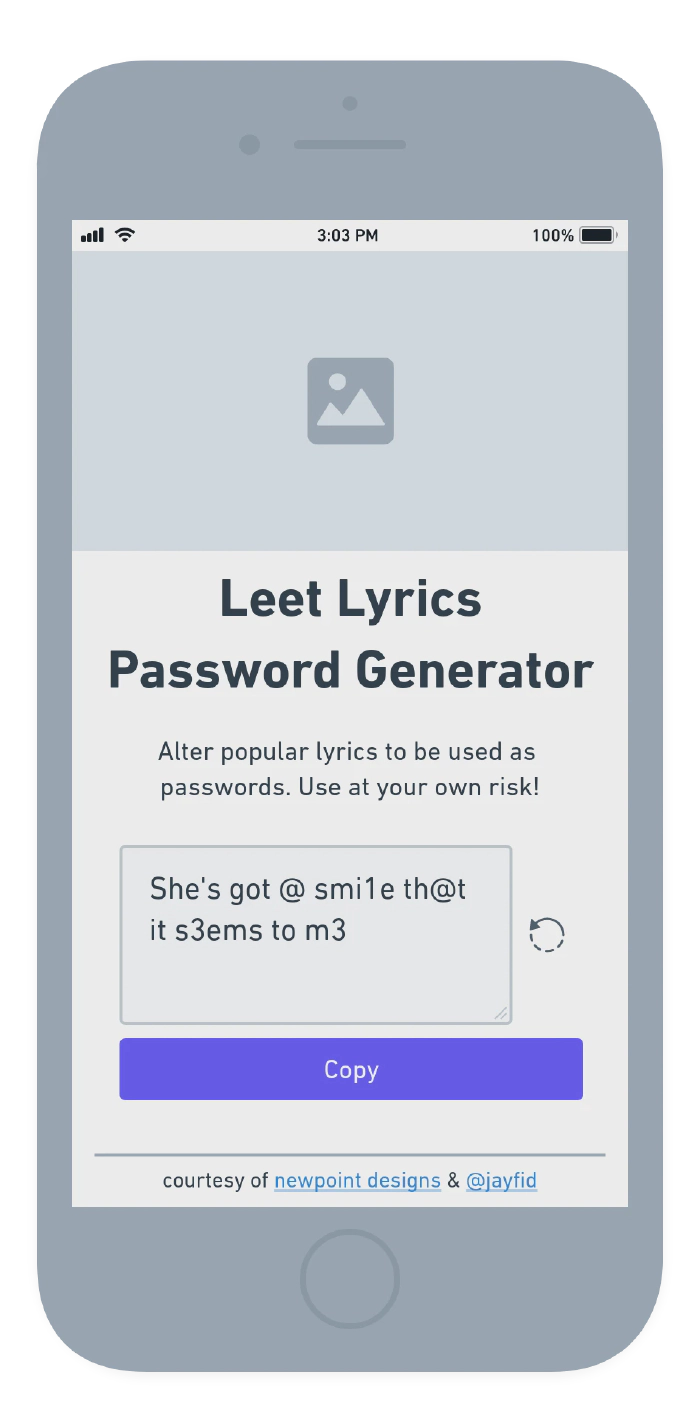
Basic wireframe of the frontend.
✖
Basic wireframe of the frontend.
I needed to decide on the frameworks for the frontend. Since it’s fairly lightweight, I opted for a basic webpack frontend using some bespoke html/js/css. I’m forgoing anything more complex because of the issue I ran into at the start of this project - more involved tool chains don’t age well, and end up needing to be rebuilt within a few years. I would build the dependencies into a binary that gets checked into source control, but that’s a project for another day.
I started by setting up the git repo and configuring the skeleton of the site. The site would be hosted on AWS, so I created an S3 bucket and cloudfront distribution to store and serve the site files. I purchased the domain leet-lyrics.com and set up the AWS SSL cert. At that point, I could verify that the hosting worked.
Proved that the hosting works as expected.
✖
Proved that the hosting works as expected.
I added in some HTML to match the mockups I created earlier, and got something that looks like this:
The base HTML is in place.
✖
The base HTML is in place.
Not too pretty yet, but it’s definitely progress! A quick pass of adding styling and a header image made it look more like a real website.
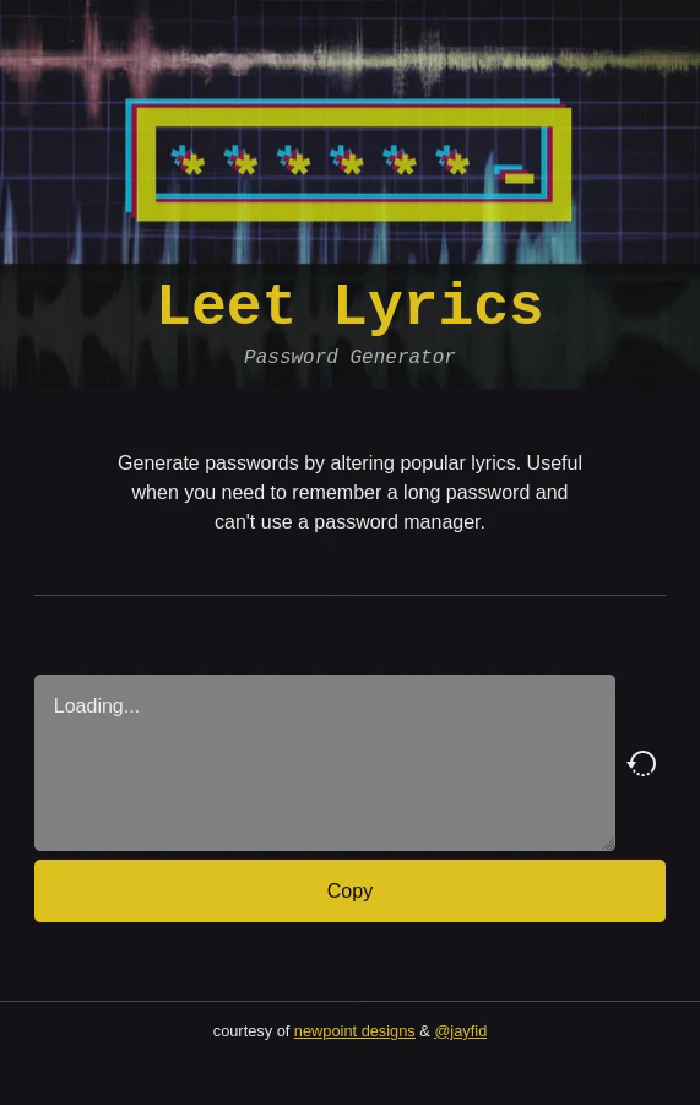
Some CSS has been added.
✖
Some CSS has been added.
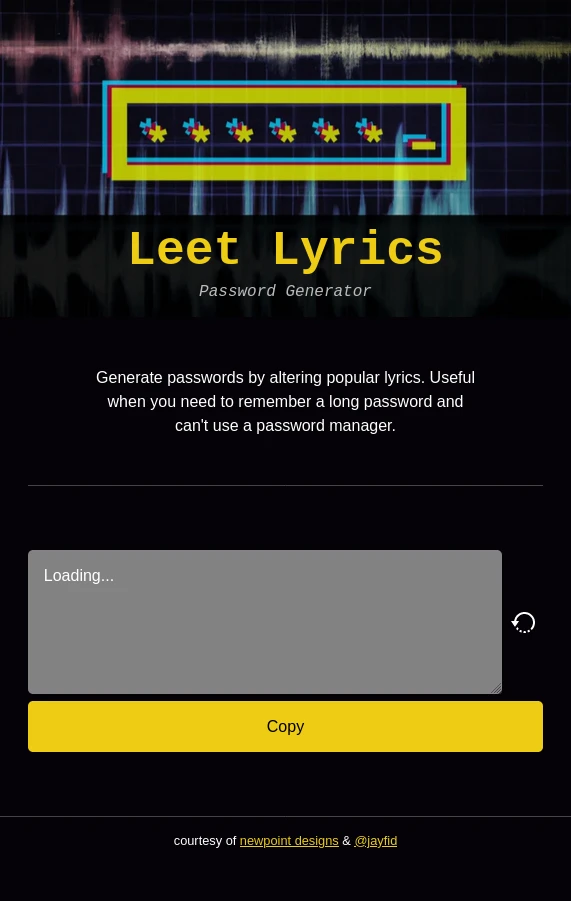
I hooked up the javascript that supplies the functionality, with the caveat that the list of lyrics was a JS Promise that resolves a list of strings. I would need to update that once the API was ready. I also tweaked some styling to be a bit more responsive and display the whole site on an iPhone 11’s screen.
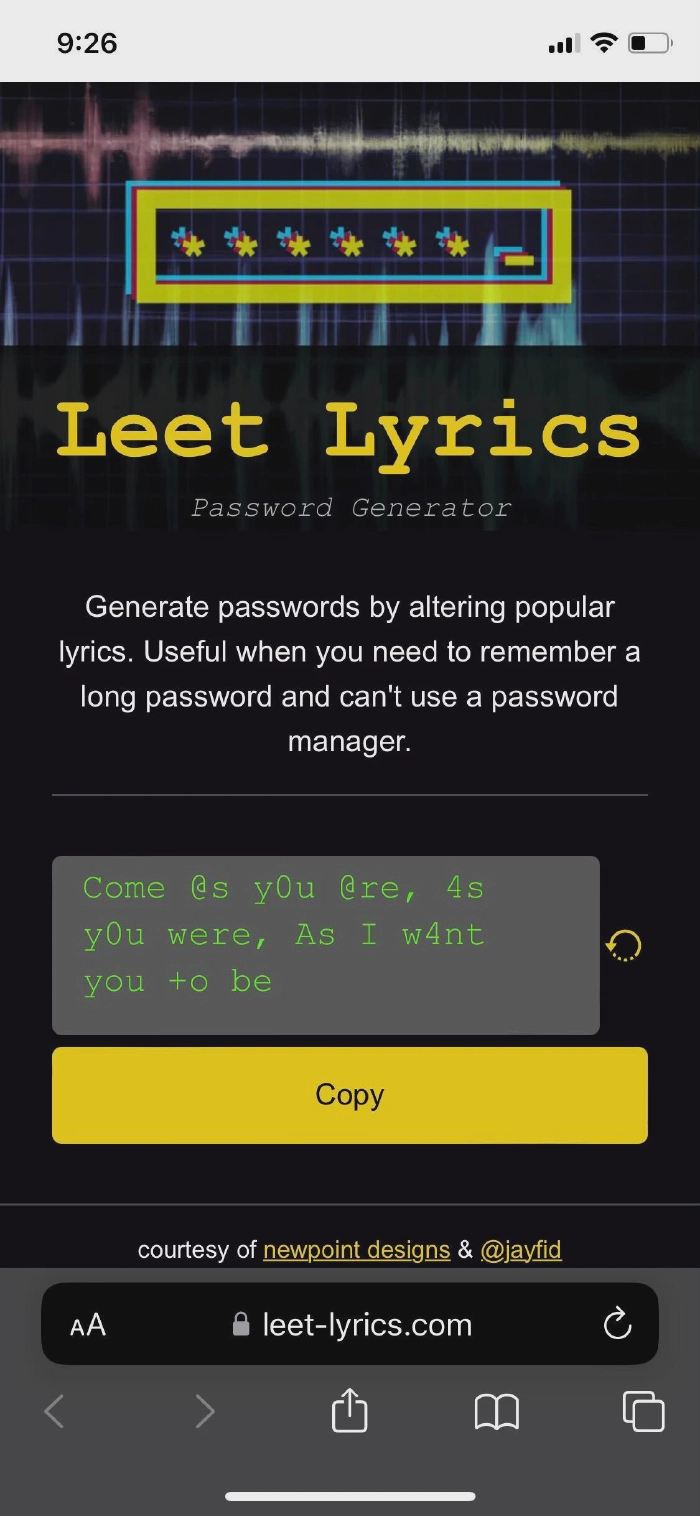
Tweaked CSS so everything fits on one page.
✖
Tweaked CSS so everything fits on one page.
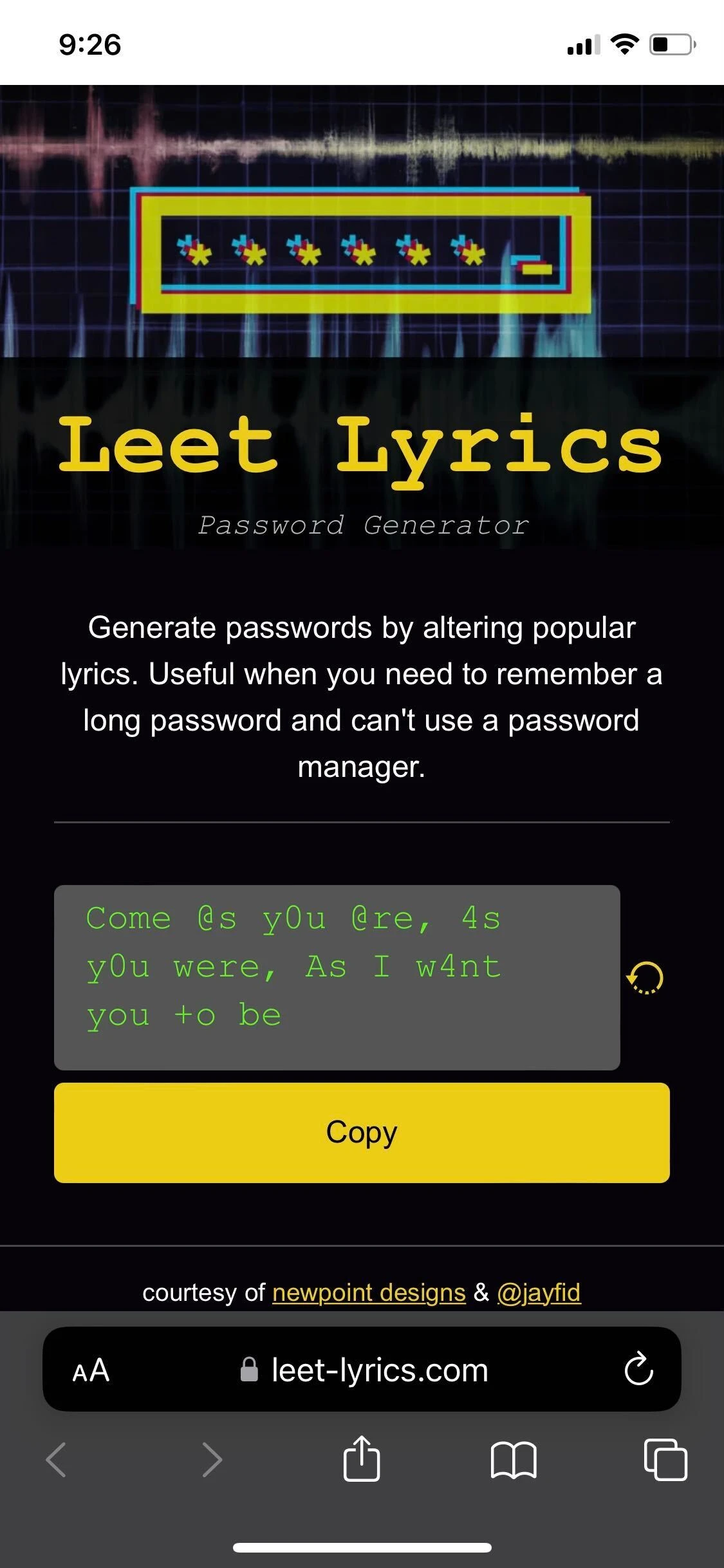
At this point, I have a working site that reads a list of hard-coded lyrics, randomly replaces characters with their leet-speak equivalent, and displays the result to the user along with a button to copy the password to their clipboard.
On to the API!
API
I compiled a basic list of API requirements:
- The population script (that I’ll get to later) can save lyrics to persistent storage
- I can manually mark lyrics that I don’t think fit, and prevent them from being re-added in the future
- Each lyric record is unique
- The API endpoint can query for a chunk of random lyrics
- The API endpoint can escape characters and return a JSON response
- There’s room to expand the schema in the future, in case I add something like a “Genre” select feature
- The whole thing runs on AWS without needing to perform manual maintenance, and ideally in the free tier
I considered DynamoDB, but I didn’t think it would offer the random select capability I wanted. The implementation I could get up and running the quickest was an API gateway endpoint hooked up to a lambda that can query a MySQL RDS instance. The population script can run as a separate lambda, and I can kick that off as needed.
To check that the infrastructure worked, I seeded a dozen or so lyrics into the DB by hand using the following schema:
| Field Name | Description |
|---|---|
| id | Primary key |
| lyric | Lyric text |
| lyric_hash | Hash of the lyric text* - this field has a unique constraint on it |
| excluded | Flag indicating not to return the lyric in the API |
| created | Datetime the record was created |
* Note that the lyric hash is a quick attempt at preventing duplicated lyrics from being saved in the DB. A more robust unique key would include better identifying info, like an artist name, track name, or ISRC, but I decided that I can live with this naive approach and the 1.47*10-29 chance of a hash collision.
In setting up the infrastructure, I created:
- a free-tier t3.micro AWS MySQL RDS as the persistent data store
- a VPC along with security groups (since I’ve been meaning to do that for a variety of personal projects)
- a free-tier EC2 instance that I can SSH into to use as a home base for running ad-hoc queries and scripts.
- a new git repo to store the lambda code and test data
- an ECR repository to store the image I’ll use for the lambda
- a new API gateway, route, and custom subdomain, which points at the lambda.
With everything wired up, it was time to test it out! A GET request to the new endpoint successfully returned a JSON response (YAY!), so I was in business! I replaced the hardcoded list in the website with a call to the new endpoint, and pushed it live. With everything working, I could move on to the final step, adding some live data!
Lyrics
DISCLAIMER
Lyrics are serious business! Despite popular lyrics being common knowledge, the business of lyrics is a very real, very litigious industry. Record labels maintain databases of their lyrics associated with their IP, and certain companies’ entire business models revolve around licensing and distributing those lyrics. You can assume that all of the lyrics I use in this app were hand typed to the best of my memory, and manually inserted into my database. However, below I’ll go into how this process could potentially be done programmatically.
The curation of a dataset is a much different problem than wiring up a frontend to talk to a backend. Practical considerations around the selection criteria would take a ton of time to perfect. It would also require plenty of API hopping and web scraping.
Ideally passphrases should be longer than “mmmbop” and shorter than “We’re just two lost souls swimming in a fish bowl, year after year, Running over the same old ground.”.
One problem is that many lyric websites just list the full lyrics of every song, not limited to the most memorable lines. And memorable bits aren’t all one line long. I would need to do some extra discovery to determine the most popular lines from the most popular songs.
There’s also a multitude of smaller issues to address to make a truly healthy dataset. Take the following excerpt from Joe Cocker’s You are so beautiful:
| |
The first and last lines would make decent bases for passphrases, but the second line is too short. And looking at Rihanna’s _Birthday Cake__:
| |
You can see that one of these things is not like the other… Despite the string length that can be used to filter out line 2, we may also want to determine how many unique words or characters are used in each line, and whether or not that would affect the usability of the passwords.
In the interest of containing this portion of the project to one afternoon, I decided that I would be happy if the dataset met the following criteria:
= 10,000 unique lyrics that are, for the most part, recognizable
- lyrics are between 3 and 8 words, and under 40 chars
- lyrics don’t contain racism/sexism
To start off, I needed a base dataset to work off with. Luckily, the top songs of the last 60 years have been curated into billboard rankings and playlists. It was simple enough to identify a few of these lists and scrape the track and artist names from them.
With that list in hand, a public API was searched using those artist and track
names. Some fuzzy matching was necessary to match API results when the names
vary slightly across databases. Finding an API’s record of a track led me to the
lyrics, and in turn, each line of the lyrics was used in a query to a search
engine to roughly determine popularity. The query, using a pattern similar to
"{lyric line}" AND "{Artist Name}", found the most commonly repeated lyric
lines across the internet. Using that as a basic metric for what’s popular, I
created my final list. At that point, I just had to store the results in the
database.
And that’s it! Leet Lyrics is online!
Summary
With the final brick in place, I can finally step back and admire my work. I’m pretty happy with how everything turned out, especially since it was done as I got free time over the course of a few days. Using popular frameworks and cloud hosting, I was able to quickly deploy live components. And by planning ahead and breaking up the work in a clear way, I was able to spend my time building without wasted effort. Also, I was able to dabble in designing features and UI’s, which, while not my specialty, can be a lot of fun.
I also think it’s important to reflect on why the original repo fell into disrepair. The glut of “legacy” code that accumulates over the years will only serve to slow down future endeavors, so any practices that can help prevent future maintenance work are valuable. In this case, the old site was a victim of changes in the nodejs and python landscape.
The replacement of gulp by webpack, and the replacement of python2 by python3 converged and decimated the toolchain of the original repo. Maybe future projects shouldn’t assume that a language will be installed (python2) or that packages will remain available and up to date (gulp/gulp-sass). Maybe the solution is to use something like a Go binary and check it into source control, that way your toolchain should remain usable, even if everything outside of it changes.
Perhaps that can be a future blog post. Anyway, thanks for reading and stay tuned for more!