The Evolution and Structure of Distributed Platforms: Part 3 - The Maintenance Crunch

Table of Contents
Tech-enabled companies have collectively learned to scale up and out, horizontally and vertically, across physical and virtual boundaries. Our next crucial evolution is in our ability to reckon with the sheer volume of everything we’ve built at-scale. With the advent of AI-powered contributions piling even more on top of existing catalogs, the visibility and tangibility of our systems is swiftly eroding.
Overview
This will be the third entry in my series covering the history of the industry’s approach to organized development of large systems. As a brief summary of part 2, we’ve gone from building one or two monolithic things to building very very many small things. Our success in this area is visible in the ability to quickly define, template, and launch pieces of larger systems. For example, a simple cloud-hosted function can go from idea to production deployment in a matter of minutes. That time frame swells depending on each organization’s stack, but the fact stands that we’ve been able to make an abundance of things at a rapid clip for several years.
This is a moment for congratulations, reflection, and planning. Congrats! We’ve made it to the end of one problem! Now onto the next one. And the next problem comes from the promise of distributed architecture being realized. We’ve built more things, faster, than we can possibly manage.
Established tech companies are grappling with this in their own ways. Large tech-enabled companies are also now looking for ways to balance continual maintenance with their other “continual-” practices (i.e. integration / deployment). Spotify was one of the first to create open source software targeting this problem space. Their Backstage framework was released in late 2020, and they have since launched an enterprise option based upon it. In the same time, a handful of similar offerings have come out and are now vying for position as top “Developer Portal” services and frameworks.
Developer Portal has become a common name for the type of platform that I’ll be describing. However, the complete implementation I envision is more of an Enterprise Resource Planning system.
There are already many qualitative comparisons of existing platforms out there, so in this post I’ll focus on what I see as the key features that these platforms should be aiming to provide.
How do we want to scale?
First of all, what are we trying to scale up, and what should the organizational impact be? The practices of the last decade have caused a common pattern to emerge where small teams of engineers have built out solutions in isolation. Over the course of years, solutions like these require a steady cadence of ad-hoc maintenance. Additionally, these solutions accumulate into a wide swath of applications that requires long term investment. The overarching goal of a Developer Portal should be to bring together the inventories that comprise these applications such that long term maintenance and management can be predictably planned for and, ultimately, automated. While tackling the large problem of coordinating effort across thousands of distributed components, we should also aim to improve the overall reliability and competency of the org.
- Component ℹ️
A self-contained building block of a distributed architecture
e.g. An API, a cloud function, or a frontend
The base platform should accommodate growth in the number of developers and the size of the system without linearly adding cost. The larger business goal is to be able to pull levers that affect the overall throughput of the department in a reliable manner. We already know where we can’t scale - a higher budget to hire more engineers to inflate team sizes has diminishing returns. Incorporating consulting agencies works similarly. New teams can create more pieces indefinitely, but the long term expense of managing these net-new components should be made somewhat predictable.
Additionally, when changing team size or responsibilities is the correct action to take, the Developer Portal should ease the onboarding/offboarding process by creating visibility into what exists and who the owners are. Internal project handoffs should also be simplified by having a centralized catalog that acts as an inventory and record of ownership.
Catalog Population
A key piece of making the shift from bespoke tribal management to a Developer Portal is the initial inventorying of everything that is currently running. This is crucial to get right because it likely requires the largest upfront investment in the process. As such, it should be done comprehensively and completely within a set amount of time, and not incur long-tail costs. A comprehensive catalog would include the components that comprise the system in its entirety, including: code; deployments; and integrations. A complete catalog should blend data from numerous sources, namely: source-code repos; deployment platforms; and integrated 3rd party services, such as logging and security scanning tools.
To tackle this step, we’ll need to evaluate the landscape of what we’re dealing with. Most organizations today would have many components that are built as slightly customized instances of templated code. Microservices have been created from example boilerplates that have changed over time. There’s probably a glut of mostly homogenous components alongside some outliers that defy easy categorization. Whether an organization uses a home-brewed or licensed Developer Portal, populating this catalog will require custom tooling and manual data review.
Doing this work should also spark discussions over ownership of components that were built by now-disbanded teams. Understanding who owns what, and enforcing full ownership across the catalog will be important for planning upcoming maintenance hours and for future development work.
As an aside, some Developer Portals (ie Backstage) tout features around becoming the new central documentation hub. I would argue that the Developer Portal should link to existing documentation rather than becoming yet another documentation source, as generating documentation is a full initiative unto itself. It’s just as likely to become a documentation graveyard as any of the other viable but under-utilized documentation options at our disposal.
Once the catalog is populated, processes would need to be put in place to make sure that new components are automatically added to the catalog and that changes to inventoried components propagate to the catalog. The implementation of these processes depends greatly on the way the catalog population is performed. There are two high level approaches that can impact this. The first is “scanning” - where tools are used to scan for components to add to the catalog. The other is “configuration”, where components are individually updated and added to the catalog. The method of keeping the catalog up to date depends greatly on whether the scanner needs to run and know what to look for, or if each component needs to have its configuration updated in a way that would reflect in the catalog.
Runtime Support Graph
During the cataloging process, the question of what to track will come up. What are core pieces of knowledge to catalog? From an investment perspective, costs can be expected to increase as dependencies and areas of expertise are added to the catalog. Future maintenance initiatives will be defined by what is currently running. Some critical data points are:
- Languages - The programming languages the organization utilizes, and the supported versions of those languages
- Frameworks - Each language has major frameworks that are commonly used for APIs, tests, ORMs, etc.
- Operating Systems - Development and deployment environments must be built on one or more base operating systems
- Cloud Providers - Deployments and resources based on the offerings of cloud platforms (i.e. AWS, Azure, GCP)
Each of these have their own “maintenance profiles”, or patterns of change that demand maintenance attention from the org. Languages have windows of support for each version. Similarly, frameworks and operating systems may need to be updated on semi-regular intervals. Cloud providers offer their own windows of support per service that require continual maintenance. These data points should be first class citizens in the modeling of the system. Ideally it would be trivial to answer the question “What’s running in production on Centos7 with a Ruby version below 3.2.0?”
Homogeneity of System Components
Once components have been cataloged, the next goal should be to normalize their structure such that maintenance can be performed in bulk. Getting similar components into a shape so patches can be issued en masse is a one-time investment that will prevent a linearly scaling amount of repetitive maintenance work later. If possible, components should have a versioned base that can be edited once and pushed as patches to all existing instances of that component.
During this exercise, practices should be put in place to make repetitive maintenance work more efficient. Updates that have traditionally been performed piecemeal should instead be able to be rolled out in bulk. As an example, CI/CD practices for team-managed components can start to break down as vulnerability scans continually flag new security issues. Without bulk maintenance, each team would need to triage each component that they manage. If a new vulnerability affects a commonly used language, framework, or operating system then there should exist a response that can fix all of the instances it affects with minimal time and effort. Similarly, if component templates also define their infrastructure, then maintenance of deployed environments can be applied across the board on a schedule.
This is all a case for strict templating of components within the org. Consider the component diagrammed below:
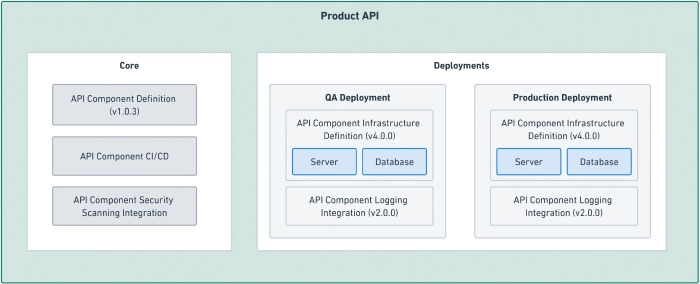
An example component from the catalog, with its core pieces and deployments as related data.
✖
An example component from the catalog, with its core pieces and deployments as related data.
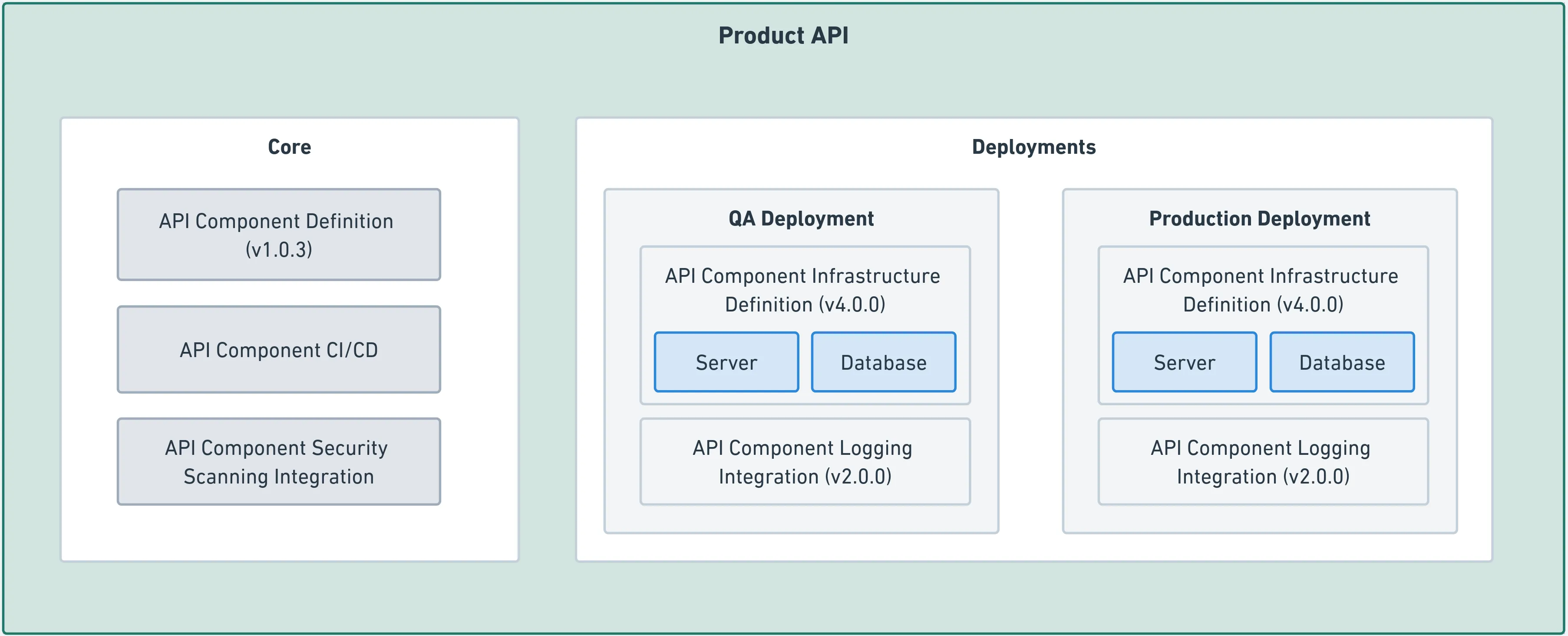
The component itself is an instance of a component type, the version of the template it’s based on, the 3rd party tool integrations it uses, and each of its deployments. It would have the benefit of incorporating the productionized best practices of the org from its templates. Maintenance targeting the “scaffolding” of the service is something that can be tackled as a coordinated campaign, and it should be visible within the scope of the larger system what work is still pending. Upgrades to the code or infrastructure templates can be applied as patches. If done purposely, it could also be possible to alleviate vendor lock-in via this approach. For example, if the logging service vendor changes, it can be a matter of changing the configuration of the component, which is a change that could be broadly applied across components in the catalog.
Support patches should be applicable by component type. Consider the following example. The Developer Portal defines a Django-based Microservice template. 100 microservices have been built and deployed using the template. If a security patch comes out for the django framework, that would require 100 separate pieces of work to be performed to address the upgrade in every microservice. The goal of a Developer Portal is to isolate and eliminate this type of work so that time can be spent on more important initiatives. If testing and CI/CD are set up properly, then it should be risk-free to automatically apply and roll out these patches. Builds that fail should be in the minority and those failures should proactively alert the team that owns them.
I detailed some specific component types in part 2. They each have their own considerations, but a few guidelines should hold true across all of them. The ability to scale the org is going to come from conformity in component implementation. It will be easier to maintain 100 instances of the same component than 100 customized versions. Activities like upgrading library versions or patching common files should be something that can roll out to N number implementations without taking hours of developer time per instance.
Tooling for each component should offer development, CI/CD, and deployment considerations. Because there are multiple environments to support, containerization is an ideal solution for tooling that can run independent of architecture and OS combinations. Basic tooling must include utilities for static code analysis, testing, and building each component type.
Anatomy of a Developer Portal
The Developer Portal itself may or may not be accounted for in its own catalog. Regardless, there are a few features that must be present.
A central database of the current state of the overall system must exist, and it should be able to report on the changes to core metrics over time.
Projects that bring together multiple components should be represented as Applications and have unified graphs that make discovery of project topology and health a simple task.
User access should come from the orgs standard user management system, such as Active Directory. Notification management should exist so component owners can be proactively notified about relevant news. To this end, teams should also be tracked in the Developer Portal along with team-level contact information.
Ideally, large maintenance efforts could be tracked in the Developer Portal. If a large number of system components need to be migrated off of a deprecated testing framework, it should be simple to define the campaign in the Developer Portal, track the progress of the migration, and send reminders to teams.
Long Term Benefits
Over time, the investment in a Developer Platform should reduce investment in operational costs while raising the limits of operational complexity. A typical issue in outsourced engineering projects has been long term value. While the initial investment is lower, the ability to understand or grow systems built under that paradigm greatly diminishes after the first couple years. By inventorying systems and keeping them active, their overall lifetime extends. This means less time and money is spent rebuilding and replacing systems that can no longer be maintained. Fewer hours are spent maintaining the comprehensive catalog, and the hours that are spent are done so more efficiently and with greater oversight.
When components are findable, teams will spend less time rebuilding solutions that have already been developed. Organization of teams and responsibilities can have greater top-down insight. There is also the opportunity to gather metrics from the centralized system so decisions can be informed by meaningful data.
The overall security, compliance, and governance of the org’s technology can be quantified and used when planning budgets or purchasing support.
Additionally, the integration of AI tools into existing systems would greatly benefit from having a centralized listing of the current components.
What’s Next
Check out part 4 for more…